I decided a while back to publish the music I’m writing, if nothing else as a way of keeping myself honest. So, here’s a little piece of fluff I wrote just to play with time signatures—alternating 5/8 and 6/8 has a nice drive to it. It’s played by my music teacher.
Thursday, December 25, 2008
Saturday, December 20, 2008

Tuesday, December 16, 2008
Ruby 1.9 can check your indentation
All Ruby programmers regularly encounter the mystical error “syntax error, unexpected $end, expecting keyword_end.” We know what it means: we left off an end somewhere in the code. As Ruby compiled our source, it keeps track of nesting, and when it reached the end of file ($end), it was expecting to see one more end keyword, and none was there.
So, we trundle back through the source, and after a while discover we’d deleted just one too many lines during that last edit.
Ruby 1.9 makes that easier. For example, here’s a source file:
class Example
def meth1
if Time.now.hours > 12
puts “Afternoon”
end
def meth2
# …
end
end
Run it through Ruby 1.9, and you’ll get the same old error message:
dave[RUBY3/Book 8:26:48*] ruby t.rb
t.rb:10: syntax error, unexpected $end, expecting keyword_end
But add the -w flag, and things get more interesting.
dave[RUBY3/Book 8:26:51*] ruby -w t.rb
t.rb:5: warning: mismatched indentations at ‘end’ with ‘if’ at 3
t.rb:9: warning: mismatched indentations at ‘end’ with ‘def’ at 2
t.rb:10: syntax error, unexpected $end, expecting keyword_end
It’s the small things in life…
Monday, December 1, 2008
Forking Ruby—my RubyConf Keynote is now up
Link: Forking Ruby—my RubyConf Keynote is now up
There’s a sound that no presenter wants to hear, and that’s dead silence. And that’s what greeted me when I made the suggestion in my RubyConf keynote that the community should fork the Ruby language. I think by the end of the talk, though, most people were convinced.
Am I anti Ruby? no.
Am I suggesting Matz is doing a bad job? Not in the least.
But I do think the complexity of the current language inhibits experimentation with language features. Want to implement parallel Ruby? If you do it with the current syntax and semantics, you’ll be struggling with the integration of global variables, the non-threadsafe nature of require, continuations, and so on, and so on. So before starting these kinds of experimental projects, I’m saying we should fork the language. Produce variants that let us focus in on the aspects under test. Make the new language a rich-enough subset that you can do useful work with it. Then let people play with it. Maybe the ideas are stellar, in which case we can all talk about integrating the changes back into the mainline language. And maybe the idea didn’t pan out, in which case we can quietly forget it, and we’ve done no damage to the language itself.
A mutation is an altered fork of the original. And mutations are essential to the diversity and strength of a genetic line over time. Let’s not be afraid to create Ruby mutants and let them compete.
The keynote is available from Confreaks.
Saturday, November 29, 2008
See Rails request paths in 'top'
During our sale, we had one particular request that came in and wedged the application: every time it hit, the mongrel process size zoomed steadily up to 500Mb, so we had to kill it. But finding out which request was doing this was tricky. The log files didn’t help—with the amount of traffic we were getting, it was a small needle and a large haystack.
Eventually, we found the culprit. But it would have been a lot easier if I’d thought of this hack on Friday, and not after the sale ended.
If you put this into your application controller:
before_filter :set_process_name_from_request
def set_process_name_from_request
$0 = request.path[0,16]
end
after_filter :unset_process_name_from_request
def unset_process_name_from_request
$0 = request.path[0,15] + "*"
endthen Ruby will set the cmd field in your process control block to the first 16 characters of the request path. You can then use top to see what request is being handled by each mongrel.

Once the request has been handled, an asterisk sign is appended, so you can see the last URL when a mongrel becomes idle.

If your version of top doesn’t show the short command by default, use the c keyboard command to see it.
This is probably common knowledge, but I thought it was cool.
Wednesday, October 15, 2008
Fun with Ruby 1.9 Regular Expressions
I’ve reorganized the regular expression content in the new Programming Ruby, and added some cool new advanced examples. This one’s fairly straightforward, but I love the fact that I can now start refactoring my more complex patterns, removing duplication.
The stuff below is an extract from the unedited update. It’ll appear in the next beta. It follows a discussion of named groups, \k and related stuff.
There’s a trick which allows us to write subroutines inside regular expressions. Recall that we can invoke a named group using \g<name>, and we define the group using (?<name>...). Normally, the definition of the group is itself matched as part of executing the pattern. However, if you add the suffix {0} to the group, it means “zero matches of this group,” so the group is not executed when first encountered.
sentence = %r{
(?<subject> cat | dog | gerbil ){0}
(?<verb> eats | drinks| generates ){0}
(?<object> water | bones | PDFs ){0}
(?<adjective> big | small | smelly ){0}
(?<opt_adj> (\g<adjective>\s)? ){0}
The\s\g<opt_adj>\g<subject>\s\g<verb>\s\g<opt_adj>\g<object>
}x
md = sentence.match("The cat drinks water")
puts "The subject is #{md[:subject]} and the verb is #{md[:verb]}"
md = sentence.match("The big dog eats smelly bones")
puts "The adjective in the second sentence is #{md[:adjective]}"
sentence =~ "The gerbil generates big PDFs"
puts "And the object in the last is #{$~[:object]}"
produces:
The subject is cat and the verb is drinks
The adjective in the second sentence is smelly
And the object in the last is PDFs
Cool, eh?
Monday, September 8, 2008
Fun with Procs in Ruby 1.9
Ruby 1.9 adds a lot of features to Proc objects.
Currying is the ability to take a function that accepts n parameters and fffgenerate from it one of more functions with some parameter values already filled in. In Ruby 1.9, you create a curry-able proc by cthe curry method on it. If you subsequently call this curried proc with fewer parameters than it expects, it will not execute. Instead, it returns a new proc with those parameters already bound.
Let’s look at a trivial example. Here’s a proc that simply adds two values:
plus = lambda {|a,b| a + b}
puts plus[1,2]I’m using the [ ] syntax to invoke the proc with arguments, in this case 1 and 2. The code will print 3.
Now let’s have some fun.
curried_plus = plus.curry n
# create two procs based on plus, but with the first parameter
# already set to a value
plus_two = curried_plus[2]
plus_ten = curried_plus[10]
puts plus_two[3]
puts plus_ten[3]On line 1, I create a curried version of the plus proc. I then call it twice, but both times I only pass it one parameter. This means it cannot execute the body. Instead, each time it returns a new proc which is like the original, but which has the first parameter preset to either 2 or 10. In the last two lines, I call these two new procs, supplying the missing parameter. This means they can execute normally, and the code outputs 5 and 13.
You can have a lot of fun with currying, but that’s not why we’re here today.
Over the weekend, Matz added a new method to the Proc class. You can now use Proc#=== as an alias for Proc.call. So, why on earth would you want to do that? Well, remember that === is used to match terms in a case statement. Over of the AimRed blog, they noted that this feature could be used to make the matching in case statements actually execute code. In their example, they manually added the ===method to class Proc
class Proc
def ===( *parameters )
self.call( *parameters )
end
endThen you can write something like
sunday = lambda{ |time| time.wday == 0 }
monday = lambda{ |time| time.wday == 1 }
# and so on...
case Time.now
when< sunday
< puts "Day of rest"
when monday
puts "work"
# ...
endSee how that works? As Ruby executes the case statement, it looks at each of the parameters of thewhen clauses in turn. For each, it invokes its === method, passing that method the original case discriminator (Time.now in this example). But with the new === method in class Proc, this will now execute the proc, passing it Time.now as a parameter.
While updating the PickAxe, I noticed that Matz liked this so much that it is now part of 1.9. And it means we can combine this trick with currying to write some fun code:
is_weekday = lambda {|day_of_week, time| time.wday == day_of_week}.curry
sunday = is_weekday[0]
monday = is_weekday[1]
tuesday = is_weekday[2]
wednesday = is_weekday[3]
thursday = is_weekday[4]
saturday = is_weekday[6]
case Time.now
when sunday
puts "Day of rest"
when monday, tuesday, wednesday, thursday, friday
puts "Work"
when saturday
puts "chores"
endIs this incredibly efficient? Not really :) But it opens up quite an interesting set of possibilities.
Saturday, September 6, 2008
Programming is a creative activity. And, like most creative people, programmers occasionally succumb to writer’s block. You’ll sit there, spinning your wheels, trying random stuff, and knowing that you’re not really getting anywhere.
I’ve been experiencing this feeling now in a different sphere. I’ve been taking music lessons for some months now, and recently blogged my first composition (or, at least, the first I was prepared to let out into the wild).
Flush with success, I launched into my next piece. I envisaged it being a set of three pieces set in a run-down dance studio. (Don’t ask why, it just seemed to fit the mood.) The first section was 5/4 and fairly upbeat. The second section was 3/4, and was deliberately clumsy (I saw partners who couldn’t quite get it together), and the last section was 4/4, and knitted things together.
At least that was the vision. I spent weeks on this thing. I had some great themes. But I just couldn’t see my way through to the end. Every lesson I’d come in with some changes, and by the end I’d argue myself out of them.
Now I’ve been coaching developers for a while now. And I know what to suggest when some programmer reaches this kind of state. But for some reason it didn’t occur to me to apply the same advice to myself. It took my teacher to say “stop working on this for a while, and go do something fun.” He gave me an assignment. Choose a simple melody and arrange it. Come back with it finished the next week.
In the end, it was great fun. It only took an hour or so, and it totally cleared my mind. I came back triumphantly the next week with something actually finished, and it felt good.
And then, I found I could get back to the more complex piece. In fact, the first time I sat down to it, I was having so much fun I went of in a totally different direction, and I’m now trying something kind of wild. More on that later…
So, if you’re finding yourself blocked—if you’re going around in circles, or if everything you do you end up throwing away—STOP. Go do something else. Something simple. Something fun. Clear your mind, and remember what it is to enjoy your work.
(And, if you’re interested, the fluff piece that cleared my logjam is an arrangement of Shenandoah: transcript and below, played by Mike Springer.)
(Update: Chris Morris took this piece of fluff and turned it into something amazing. I think there are about three notes of mine in there somewhere…)
Sunday, June 15, 2008
Monday, June 9, 2008
Screencasting Ruby Metaprogramming

I’ve been teaching Ruby (and in particularly, metaprogramming Ruby) for almost 7 years now. And, in that time, I’ve gradually found ways of cutting through all the confusing stuff to the actual essentials. And when you do that, suddenly things get a lot simpler. I’ve always know that Ruby didn’t really have class methods and singleton methods, for example, but until recently I didn’t have a simple way to explain that.
Then, when preparing to give an Advanced Ruby Studio, my thinking crystalized. Metaprogramming in Ruby becomes simple to explain if you focus on four things:
- Objects, not classes.
- There is only one kind of method call in Ruby. The “right-then-up” rule covers everything.
- Understanding that
selfcan only be changed by a method call with a receiver or by a class or module definition makes it easy to keep track of what’s going on when metaprogramming. - Knowing that Ruby keeps an internal concept of “the current class” which is where
defdefines its methods. Knowing what changes this makes it easier to know what’s going on.
I tried this approach in a number of Studios, and refined it during some talks for RubyFools in Copenhagen and Oslo.
So Mike Clark, who’s producing our new series of screencasts, started pushing me to put this description into video. Last week I finally cleared the decks enough to record the first three episodes.
First, I have to say it was a blast. I’d never recorded this many minutes of screencast before, and I was blown away by the amount of time it takes. I was also surprised at the level of detail involved, from microphone setup (which I messed up for a couple of segments) to color matching between codecs, it was fun to learn a whole new set of technologies.
I was also surprised at how hard it was to talk to a microphone. When we write books, we always try to write as if the reader was sitting there next to us. I tried to to the same approach with the screencasts, but it takes a whole new set of skills…
What I really liked was the way that I could live code examples to illustrate points. The first episode has maybe 50/50 code and exposition, and the second and third episodes are mostly code. And the code acts as a great skeleton on which to hang the concepts. Apple-R also keeps me honest.
So, if you’re interested in how the Ruby object model really works, and want to improve your metaprogramming chops, why not check them out?
Tuesday, May 27, 2008
A while back, I was asked during an interview what I’d do if I had three months off. I said I’d take piano lessons.
Well, my wife read that and very sweetly got me some. And then reality hit home. I really do have totally uncoordinated hands. I try to play, but I’m getting nowhere.
At the same time, I still enjoy noodling around with music. So my piano teacher (in a move motivated by self-preservation, no doubt) suggested we should look at composition instead. And I’ve been having a whole bunch of fun ever since.
But then Chad Fowler reminds me that the test is having it heard, which is kind of scary. But here’s my first piece. Be gentle…
(Update: people asked for the transcription: it’s here. Some of the pedal marks are screwy: I’m using Encore, and it seems to move them around every time I save. I might well end up going back to Sibelius. Forgive any amateur mistakes.)
Thursday, May 22, 2008
New lambda syntax in Ruby 1.9
I’m slowly getting used to the new -> way of specifying lambdas in Ruby 1.9. I still feel that, as a notation, it could be clearer. (I’d personally like just plain backslash, because that looks pretty close to a real lambda character, but that’s not going to happen.) But having punctuation, rather than the wordlambda, makes a surprising difference to the way my eyes read code.
For example, you could write a method that acts like a while loop.
def my_while(cond, &body)
while cond.call
body.call
end
end In Ruby 1.8 and 1.9, you could call this as
a = 0
my_while lambda { a < 5 } do
puts a
a += 1
endBut my brain finds that seriously hard to scan. The Ruby 1.9 -> syntax makes it slightly (just slightly, mind you) better:
a = 0
my_while -> { a < 5 } do
puts a
a += 1
endI suspect this is just a question of time. In a year or so, we’ll parse the -> syntax in our heads without thinking twice. Once it does become natural, I suspect we’ll find all sorts of new uses for procs.
Monday, May 19, 2008

In the last week we shipped out two much anticipated books:Advanced Rails Recipes and Deploying Rails Applications: A Step-by-Step Guide. We’ve finally reached the kind of shipping volumes where we get special treatment at the Post Office—I’m now allowed to make deliveries around the back, driving my truck up to the loading dock between all the 50’ monsters. It’s an interesting insight into their business. The vast majority of stuff sitting out there during the day is the free advertising fliers that get added to your mail—pallet upon pallet of them. If we want to save the forests, finding some way of banning those things would be a start. (But, of course, they probably subsidize the mail, so doing so would double the cost of postage. In this case, that’s a price I might be willing to pay.)
Also (getting back on topic), Mike Clark has made a 12 minute video highlighting some of the more visual recipes in his book. Check out the link on the book’s home page.
Sunday, May 18, 2008
Code in Presentations, Part II
OK, enough people asked, so…
http://github.com/pragdave/codex/tree/master
Every good relationship starts by establishing some basic ground rules. Here’s ours: you’re on your own. Totally, bleakly, and emptily on your own. No support. No requests for enhancements. No cards on your birthday. And I want to continue to see other developers.
But I will consider patches. In particular splitting it up so it can be installed as a Gem would be really nice. You’d probably need some kind of generator to create a new slide show. I’d guess would contain just a Rakefile, a slides/ directory and an html/ directory.
Enjoy.
Friday, May 16, 2008
Zachary has been studying karate for almost 5 years now. About 2 months ago he got cleared to test for his black belt. Since then, he’s been in intense training, leading up to two consecutive weekends of testing. Last week was the formal stuff—a verbal presentation and his kata. This weekend was the fighting part. He had to go through a set of eight self-defenses he’d created, then do some grappling. The session finished with 15 consecutive 2 minute sparring sessions with a mixture of classmates and black belts, with a 30 second break between each, topped of with a no-holds sparing session with an instructor, followed by a session of two-on-one sparring. It’s been a couple of hours, and I think all of our heart rates are all still elevated.
He has worked so incredibly hard for this. I’m so proud of him.
Now I have to work out how to live with a teenage son who is both bigger than me and formally trained in martial arts :)
Thursday, May 15, 2008
Our take on presenting code
Back in March, Jim Weirich posted some notes on a clever technique for getting code into Keynote presentations. It struck a chord with me, because I’ve been suffering the same problem for a long time now. Eventually, the pain of putting together the Studio content with Mike Clark and Chad Fowler drove me to find a solution. (The pain wasn’t working with Mike and Chad—it was creating and keeping up to date many hundreds of slides, most of which contained code.)
The solution we went with was based on the way we do code in the Bookshelf books. Rather than embedding the code in the slides, we write regular old programs. Then, in the slide material, we reference the source file (and optionally say which section of that source file), and the appropriate code gets dragged into the slide, syntax highlighted, and hyperlinked back to our editor. Here’s how it works.
Create Your Material
We’ve given up using Keynote and Powerpoint. They’re a pain with version control, and they make it easy to fall into the eye-candy trap, favoring glitz over content. Instead, we create our material is plain text files using Textile markup. Typically we use one file per major topic, and the use an index file to bring all these individual files together into a single overall presentation.
Within the material, we can include material from external files using the :code directive.
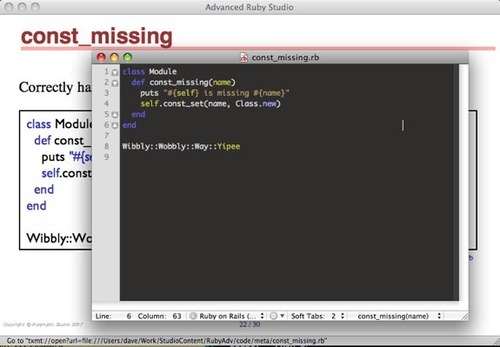
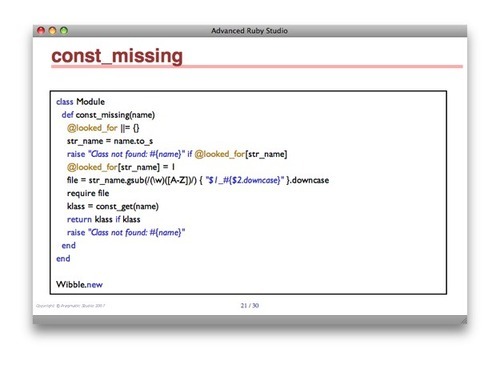
Here’s the source for an individual slide:
h1. const_missing
Correctly handles nested modules
:code code/meta/const_missing.rband here’s what appears on the screen:

The code gets inserted onto the slide and is syntax highlighted. The blue text below the box shows the file name (so attendees can find it in their collateral material). It’s also a txmt: hyperlink—click it and the file opens in Textmate, so we can edit and run it.
Using Parts of a Source File
You often just want to show part of a larger source file. We do that by including START:tag and END:tagcomments in the original source. (This works in any language, and not just Ruby source). In the slide markup, you indicate the part(s) you want to include in square brackets after the file name:
h1. method_missing
:code code/meta/my_ostruct.rb[impl class="code-small"]This says to look at the source file code/meta/my_ostruct.rb and only include on the slide the stuff between START:impl and comments. We’ll also display it using the CSS class code-small.
The ability to include parts of code is invaluable when you’re doing a sequence of slides that builds a solution: you can show each part of a source file in turn.
Building the Presentation
The toolchain that takes all this is remarkably simple, because most of the work is done for us. We use a simple Ruby script that takes our original slides, embeds the source code from external files, and then runs Textile to produce an HTML version. We then add a header to that HTML that drags in two incredibly useful Javascript libraries.
For the presentation itself, we use Eric Meyer’s S5 system. It gives us nice looking slides, simple to use navigation, and lets us present in our own browsers or (potentially) on our students’.
For the syntax highlighting of code, we use SyntaxHighlighter. This clever piece of code doesn;t require you to mark up the code elements inthe HTML. Instead you just flag your <pre> blocks with an appropriate class and it does the parsing and highlighting in the browser. It means that really large decks can be a little slow to load (but the still beat Keynote on elaspsed time), but it also means your HTML is really clean.
Finally, we have a Rake task that lets us built the whole presentation or just individual chapters.
The whole thing took about 4 hours to get working, and probably another 4 hours on and off to tweak it based on experience. The code’s not really in a state that can be released (so please don’t ask), but it wouldn’t take much to produce something you could do the same with.
It Actually Works in Practice!
So far, we’ve done two studios using this stuff (Advanced Ruby and Erlang), and I’ve used it in a number of conference presentations. I wouldn’t switch back to regular presentation software for any code-based talk. (I’ll still use Keynote for non-code slides, though.)
A Few More Slides
Here’s the source:
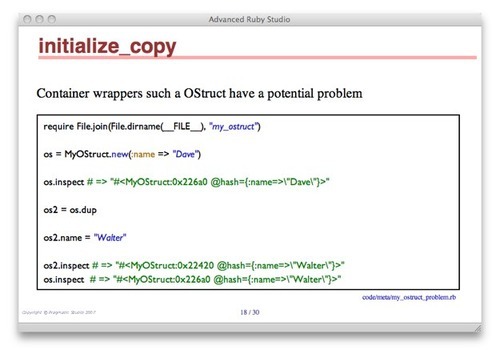
h1. initialize_copyh1. initialize_copy
Container wrappers such a OStruct have a potential problem
:code code/meta/my_ostruct_problem.rb[class=code-small]
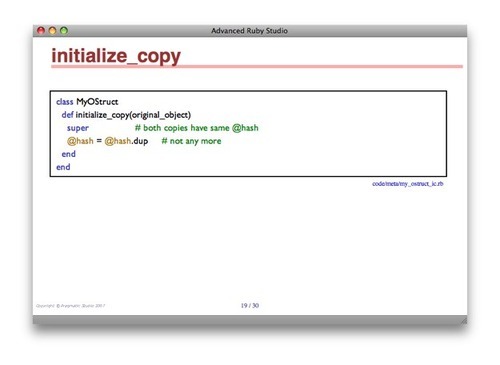
:code code/meta/my_ostruct_ic.rb[impl class=”code-small”
h1. const_missing
* Module method whenever undefined constant references in that module
** (Module is a module, and acts as a global place for @const_missing@)
* Mostly used to autoload classes
* Not as easy as it looks (Rails’ @dependencies.rb@ is 500 lines long
h1. const_missing
:code code/meta/const_missing_autoload.rb[class=code-small]
And here are the resulting slides:

Sunday, April 27, 2008
Shoulda used this earlier
In many ways, testing software is like going out and getting exercise. You know you should do it, and you know it does you good, but it’s also pretty easy to find an excuse to skip it (I’ll make it up tomorrow).
So anything that makes testing easier is good, because it cuts down on the excuses not to do it.
One thing I’ve never really liked about the conventional xUnit-style testing frameworks was the setup and teardown structure. In these frameworks, a test case is a class, and setup and teardown are implemented by methods in that class. Each test is also a method, so the basic flow is
for each test method in the class
run setup
run the test method
run teardown
end
Nice and simple. Each test method got the benefit of a standard environment created by the setup method, and the teardown method got the job of tidying up after.
Except… when I’m writing tests, I typically want to set up lots of different scenarios. I’ll want A and B and C, then A and B but not C, then A and not B, then A and D, and so on. I had two choices—write lots of test case classes, using subclassing to inherit common setup behavior, or write per-test method setup code (often factored out into helpers). In the end, I almost always did the latter, And that was tedious, and it made it harder to see the tests for the setup code.
I flirted with RSpec. Its spec framework seemed to have what I wanted. But I just couldn’t get myself to enjoy using it. (I think it’s a cat people/dog people kind of thing)
Enter shoulda
Then, a couple of weeks back, Mike Clark and Chad Fowler introduced me to shoulda. Shoulda isn’t a testing framework. Instead, it extends Ruby’s existing Test::Unit framework with the idea of testcontexts. A context is a section of your test case where all the test methods have something in common. At it simplest, a context could be simply used as an annotation device (and, yes, this is a silly example):
context "My factorial method" do
should "return 1 when passed 0" do
assert_equal 1, fact(0)
end
should "return 1 when passed 1" do
assert_equal 1, fact(1)
end
should "return 6 when passed 3" do
assert_equal 6, fact(3)
end
end
The stuff in a context can share common setup code—just write a setup block.
class CartTest < Test::Unit::TestCase
context "An empty cart" do
setup do
@cart = orders(:wilmas_empty_cart)
end
should "have no line items" do
assert_equal 0, @cart.line_items.size
end
should "have a zero price" do
assert_equal 0, @cart.price
end
end
context "Some other context..." ...
end
end
So now, within a single test case I can set up multiple contexts, and each context can have its own environment.
But, take it back to my original problem. I often want to set up hierarchies of related environments for my tests. The shaoulda code handles this wonderfully, because it lets me nest contexts. For example, I’m adding a feature to our store that gives customers some additional information if, during checkout, their credit card transaction was initially rejected because the address was wrong, and was then accepted when they fixed the address. I wanted two tests, one without the prior address error, and one with.
To set up this environment, I needed to set up a shopping cart, create a dummy response from our payment gateway, and post that response to the application. In the case of the prior address error, I also wanted to inject an entry containing that error into the transactions associated with the order prior to generating the response.
With shoulda, I simply created some nested contexts. The top level context did the shared setup, and the inner contexts then set up appropriate environments for their tests. It looked like this:
context "Checking out" do
setup do
@cart = cart_named(:freds_full_cart)
@cart.prepare_for_store_authorize!
@params = approved_authnet_response(@cart)
end
context "with no AVS errors in CC transaction history" do
setup do
post :post_from_authnet_authorize, @params
end
should_redirect_to "{:action => :receipt}"
end
context "with AVS errors in CC transaction history" do
setup do
avs_error = CcTransaction.new(:response_code => 2, :response_reason_code => 27)
@cart.cc_transactions << avs_error
post :post_from_authnet_authorize, @params
end
should_redirect_to "{:action => :explain_avs_mismatch}"
end
end
The outer setup gets run before the execution of each of the inner contexts. And the setup in the inner contexts gets run when running that context. And shoulda keeps track of it all, so I get very natural error messages if an assertion fails. For example, if the test in the second context above fails, I’d get
Checking out with AVS errors in CC transaction history should
redirect to "{:action => :explain_avs_mixsmatch}".
So, now, I can finally set up my hierarchies of test environments in a natural way. It isn’t revolutionary. It’s just one less excuse for not testing…
Tuesday, April 8, 2008
BabyDoc
One of the fun thigs about updating the PickAxe is getting to come up with examples to show the various APIs in action. Here’s a very silly example of using Ripper’s event-based API to extract comments that are associated with basic class definitions. It clearly has holes (it doesn’t handle class A::B::C, for instance) but it’s fairly easy to see how to add a proper state machine and produce something that might be interesting to play with…
require 'ripper'
# This class handles parser events, extracting
# comments and attaching them to class definitions
class BabyRDoc < Ripper::Filter
def initialize(*)
super
reset_state
end
def on_default(event, token, output)
reset_state
output
end
def on_sp(token, output) output end
alias on_nil on_sp
def on_comment(comment, output)
@comment << comment.sub(/^\s*#\s*/, " ")
output
end
def on_kw(name, output)
@expecting_class_name = (name == 'class')
output
end
def on_const(name, output)
if @expecting_class_name
output << "#{name}:\n"
output << @comment
end
reset_state
output
end
private
def reset_state
@comment = ""
@expecting_class_name = false
end
end
BabyRDoc.new(File.read(__FILE__)).parse(STDOUT)
Run this with Ruby 1.9 (or, I guess, 1.8 with Ripper installed), and you’ll see
BabyRDoc:
This class handles parser events, extracting
comments and attaching them to class definitions
Monday, April 7, 2008
Fun with Ruby 1.9 File Encodings
Ruby 1.9 allows you to specify the character encodings of I/O streams, strings, regexps, symbols, and so on. It also lets you specify the encoding of individual source files (and a complete application can be built from many files, each with different character encodings). Expect to start seeing a rash of obscure source code, at least until the initial excitement abates and cooler thinking prevails.
In the meantime, we can get away with
# encoding: utf-8
require 'mathn'
class Numeric
def ℃
(self - 32) * 5/9
end
def ℉
self * 9/5 + 32
end
end
puts 212.℃
puts 100.℉
Or, for those who’d like a peek at the start of a road that eventually leads to madness:
alias ✎ puts
✎ 212.℃
✎ 100.℉I’m betting this post displays badly on about 50% of the machines that are used to view it. Which is reason enough to tread very lightly down this path…
Sunday, March 23, 2008
I'd like to apologize
Just before the weekend, I did something stupid and hurtful, and I’d like to make it right.
For the last few weeks, I’ve been getting e-mails about a book under development over at O’Reilly called Software Craftsmanship—from Apprentice to Journeyman. People kept pointing out that the main title was the same as Pete McBreen’s book (for which I wrote the foreword), and that the overall structure of the title was similar to that of The Pragmatic Programmer.
After a while, this started to get under my skin. I wasn’t so much concerned about the “journeyman” bit, but the duplication of the title just seemed wrong to me—I really liked Pete’s book, and I didn’t want to see it getting eclipsed. I complained about this to a senior editor at O’Reilly, and he said he’d bring it up with the book’s editor, who worked for him. I heard nothing back.
So, at the end of a tiring week, I wrote a blog post, complaining about the title.
That was wrong of me.
It was wrong for a number of reasons.
- I could, and probably should, have bypassed etiquette and contacted the authors directly, even though they write for a rival publisher.
- It really wasn’t any of my business.
- But, most importantly, it took something which was a kind of intellectual annoyance and turned it into something that made the authors of the book feel bad. And for that, I apologize.
This year, I’ve been the target of some cruel blog posts. Most readers of these posts viewed them as fine sport. But as the recipient of the criticism, I’m here to tell you that it hurts. It doesn’t matter whether it is based on truth or whether it isn’t. It doesn’t matter whether the person writing them knows you or is a total stranger. It hurts. Public attacks like this are virtually impossible to defend against, and that is a cruel violation. It’s cruel when it is done to you, and it’s cruel when you do it to others.
So, I of all people should have known better. I should have had the common sense to realize that my comments, aimed at a book, were going to be hurtful to the authors. It’s kind of obvious, really.
I wasn’t thinking straight, and I messed up.
So, Dave and Ade, I’m sorry for any distress I caused.
Good luck with your book.
Thursday, March 13, 2008
Source Code for that Testing Library
Ring the bells that still can ring
Forget your perfect offering
There is a crack in everything
That’s how the light gets in.
—Leonard Cohen
Yesterday, I posted on a trivial little testing library I hacked together.I’ve put the source online. Get the source through Rob’s git repository (see below).
In the meantime, I discovered a problem with the idea of intercepting comparison operators, the technique used by the expect method. Ruby doesn’t really have != and !~ methods. Instead, the parser maps(a != b) into !(a == b). This means that the ComparisonProxy cannot intercept calls to either of these. This is a problem because
expect(1) != 1actually passes, because it becomes !(expect(1) == 1), and the expect method is happy with that.
I’m betting there’s a way around this…
Update: 14:26 CDT.
- Rob Sanheim has set up a Git repository for the code. He says
I’ve put this up on github to watch what forks or releases develop around it.
git clone git://github.com/rsanheim/prag_dave_testing.git Michael Neumann suggested a way around the negated == and =~ tests using source inspection:
class ComparatorProxy
def ==(obj)
# try to get the source code position of the call
# and see if it's a != or a ==
end
end
Wednesday, March 12, 2008
Playing with a Testing Library
I’d like to be able to express my unit tests fairly naturally, using the conditional operators built into the language. So, for example, I’d want to write:
expect(factorial(5)) == 120
expect(factorial(10)) > 10000
I’d like the error messages to show both the code that caused the error and the values that caused the error. So, for example, I’d want the following (incorrect) test
expect(factorial(6)) == 600
to output something like
/Users/dave/tmp/tmc/blog_tests.rb:16
the code was: expect(factorial(6)) == 600,
but 720 != 600
and
expect(1) > 2
should say
/Users/dave/Play/tmc/blog_tests.rb:11
the code was: expect(1) > 2,
but 1 <= 2
(Note how the expression showing the actual values negates the comparison operator to make it easier to read.)
- I annotate my code with comments, so I’d like to be able to annotate my tests the same way.
expect(factorial(6)) == 600 # Deliberate bad test
should produce something like
/Users/dave/tmp/tmc/blog_tests.rb:17
Deliberate bad test
the code was: expect(factorial(6)) == 600,
but 720 != 600
Sometimes I write longer comments.
# The factorial of 6 is a special case,
# because of the labor laws in Las Vegas
expect(factorial(6)) == 600
So the resulting errors are longer, too.
/Users/dave/Play/tmc/blog_tests.rb:21
The factorial of 6 is a special case, because of the labor laws in Las Vegas
the code was: expect(factorial(6)) == 600,
but 720 != 600
I like to be able to group my tests.
testing("positive factorials") do
expect(factorial(1)) == 1
expect(factorial(2)) == 2
expect(factorial(5)) == 120
end
testing("factorial of zero") do
expect(factorial(0)) == 1
end
testing("negative factorials") do
expect(factorial(-1)) == 1
expect(factorial(-5)) == 1
end
I like the description of the group to appear along with any individual test annotation if a test fails.
testing("factorial of zero") do
# this test is deliberately wrong
expect(factorial(0)) == 0
end
will produce/Users/dave/Play/tmc/blog_tests.rb:31--while testing factorial of zero
this test is deliberately wrong
the code was: expect(factorial(0)) == 0,
but 1 != 0
I like to have the flexibility to set up the environment for a group of tests. I also like to have the idea of a global environment which doesn’t get messed up by the running of tests (so that subsequent tests can run in that environment. I don’t see why I should have to package things into methods with magic names to have that happen. Instead, why not just have transactional instance variables? That way, I can use regular methods to set up the state for a test.
@order = Order.new("Dave Thomas", "Ruby Book")
testing("normal case") do
expect(@order.valid?) == true
end
testing("missing name in order") do
@order.name = nil
expect(@order.valid?) == false
expect(@order.error) == "missing name"
end
# Check that order is reset to valid state here
expect(@order.valid?) == true
So, in the preceding case, the second
testingblock changed the@orderobject. However, once the block terminated, the object was restored to its initial (valid) state.
So, while waiting for the last day of the Rails Studio to start, I hacked together a quick proof of concept. It’s less than 100 lines of code. All the output shown here was generated by it. Is this worth developing into something usable?
Monday, March 10, 2008
The 'Language' in Domain-Specific Language Doesn't Mean English (or French, or Japanese, or ...)
I’m a really big fan of Domain-Specific Languages. Andy and I plugged them back in ‘98 when writingThe Pragmatic Programmer. I’ve written my share of them over the years, and I’ve used even more. Which is why it is distressing to see that a whole group of developers are writing DSLs (and discussing DSLs) without seeming to get one of the fundamental principles behind good DSL design.
Domain experts don’t speak a natural language
Let’s say that another way. Whenever domain experts communicate, they may seem to be speaking in English (or French, or whatever). But they are not. They are speaking jargon, a specialized language that they’ve invented as a shorthand for communicating effectively with their peers. Jargon may use English words, but these words have been warped into having very different meanings—meanings that you only learn through experience in the field.
Let’s look at some successful domain specific languages before turning our attention on the way that some DSLs are trying just a little too hard.
Success Story 1: Dependency Management in Make
The Make utility has been a mainstay of Unix software development for over 30 years. You can complain about some strange syntax rules (some of which involve the invisible difference between tabs and spaces), but it would be hard to argue that Make hasn’t had a major impact in the open source world.
At its heart, Make addresses the building of systems from components in the presence of dependencies. Make lets me express the dependencies between header files, source files, object files, libraries, and executable images. It also lets me specify the commands to execute to resolve those dependencies when certain items are missing. For example, I could say
my_prog.o: my_prog_.c common.h
extras.o: extras.c common.h
my_prog: my_prog.o extras.o
cc -o my_prog -lc my_prog.o extras.o
This example of the Make DSL says that my_prog.o depends on my_prog.c and common.h, and thatextras.o depends on extras.c and also depends on common.h. The final program, my_prog, depends on the two object files. To build the program, we have to execute the cc command on the line that follows the dependency line. No build command is needed for the object files: in this case Make knows what to do implicitly.
People who build software from source are domain experts in the area of dependencies and build commands. They need concise ways of expressing that expertise, of saying things like “if I ask you to ensure my program is up-to-date, and the common header file has been changed, then I want you to rebuild all the dependent object files before then rebuilding the main program”. Make is by no means perfect, but its longevity shows that it goes a long way as a DSL to meeting its expert’s needs.
Success Story 2: Active Record Declarations
Love it or loathe it, you have to admit that Rails has changed the game. And one reason is its extensive use of DSLs. For example, when you are writing model classes, you are claiming to be an expert on your application’s domain, and in the relationships between objects in that domain. And Rails has a nifty DSL to let you express those relationships.
class Post < ActiveRecord::Base
has_many :comments
...
end
class Comment < ActiveRecord::Base
belongs_to :post
...
end
The two lines containing has_many and belongs_to are part of a data modeling DSL provided by Rails. Behind the scenes, this simple-looking code creates a whole heap of supporting infrastructure in the application, infrastructure that allows the programmer to easily navigate and manage the relationships between (in this case) posts and comments.
At first blush, this might seem like an English-language DSL. But, despite appearances, has_many andbelongs_to are not English phrases. They are jargon from the world of modeling. They have a specific meaning in that context, a meaning that is clear to developers using Rails (because those developers take on the role of domain modeler when they start writing the application).
Success Story 3: Groovy Builders
The Groovy language has a wonderful way of expressing data in code. The builder concept lets you construct a set of nodes as a side effect of code execution. You can then express those nodes as (for example) XML, or JSON, or Swing user interfaces. Here’s a trivial example that constructs some nodes describing a person which we can then output as XML.
result = new StringWriter
xml = new groovy.xml.MarkupBuilder(result)
xml.person(category: 'employee') {
name('dave')
likes('programming')
}
println result
This would generate something like
<person category="employee">
<name>dave</name>
<likes>programming</likes>
</person>
(Jim Wierich took this idea and created the wonderful Ruby Builder library, the basis of Rails’ XML-generating templates.)
Again, we have a DSL aimed squaring at someone who knows what they are doing. If you’re creating XML, then you know that the elements can be nested, that they can have textual content, and that elements have optional attributes. The Builder DSL takes care of all the details for you—the angle brackets, any quoting, and so on—but you still have to know the underlying concepts. Again, the language of the DSL is the language of the domain.
Seduced by Language
Over the years, people have looked at DSLs and wondered just how far they can be taken. Would it be possible to create a DSL that could be used by somewhat who wasn’t a domain expert? So far, the answer is “no.” The problem is that abstractions leak—to do things in a domain, you need to know the domain. The folks who brought us Startrek TNG pretended otherwise. Jean Luc Picard used an English language DSL to talk to his food dispenser. It worked every time. But, in the real world, you know that the first time someone said “Earl Gray, hot” to this magic box, they’d be surprised when a naked English peer covered in baby oil popped out.
The reality is that languages such as English, French, and so on, are imprecise. That ambiguity makes them powerful. Because of this, whenever we try to create a DSL that looks like a natural language, we fall short. Take AppleScript as an example. On the face of it, it looks nice and expressive—we’re writing something that looks very natural. Here’s an example from the Apple example scripts.
set this_file to choose file without invisibles
try
tell application "Image Events"
launch
set this_image to open this_file
scale this_image to size 640
save this_image with icon
close this_image
end tell
on error error_message
display dialog error_message
end try
Kind of makes sense, doesn’t it? I thought so too. So, for years, I’ve been trying to get into AppleScript. I keep trying, and I keep failing. Because the language is deceptive. They try to make it English-like. But it isn’t English. It’s a programming language. And it has rules and a syntax that are very unEnglish like. There’s a major cognitive dissonance—I have to take ideas expressed in a natural language (the problem), then map them into an artificial language (the AppleScript programming model), but then write something that is a kind of faux natural language. (Piers Cawley calls these kinds of DSLs domain-specific pidgin, but my understanding is that pidgins are full languages, and our code hasn’t got that far.)
What’s the point? When you’re writing logic like this, with exception handling, command sequencing, and (in more advanced examples) conditionals and loops, then what you’re doing is programming. The domain is the world of code. If you’re not up to programming, then you shouldn’t be writing AppleScript. And if you are up to programming, then AppleScript just gets in your way.
But this isn’t a discussion of AppleScript. That’s just an example of the kind of trouble you get into when you forget what the domain is and try to create natural language DSLs.
Testing Times
Here’s a little code from a test written using the test/spec framework.
specify "should be a string" do
@result.should.be.a.kind_of String
end
specify "value should be 'cat'" do
@result.should.equal "cat"
end
It’s an elegant example of what can be done with Ruby. And, don’t get me wrong. I’m not picking on Chris here. I think he’s created a clever framework, and one that is likely to become quite popular.
But let’s look at it from a DSL point of view. What is the domain? I’m thinking it is the specification of the correct behavior of programs. And who are the domain experts? That’s a trickier question to answer. In an ideal world, it would be the business users. But, the reality is that if the business users had the time, patience, an inclination to write things at this level, they wouldn’t need programmers. Don’t kid yourselves—writing these specs is programming, and the domain experts are programmers.
As a programmer, a couple of things leap out at me from these tests. First, there’s the duplication. Thespecify lines are a form of grouping, and each contains a string documenting what that group tests. But the whole point of the DSL part of the exercise is to make that blindingly obvious anyway. Now the BDD folks say that you write the specifications first, without any content, and then gradually add the tests in the blocks as you add supporting application code. I’d suggest that you might want to look at ways of removing the eventual duplication by transforming the specification into the test.
But for me the really worrying thing is the syntax. @result.should.be.a.kind.of String. It reads like English. But it isn’t. The words are separated by periods, except the last two, where we have a space. As a programmer, I know why. But as a user, I worry about it. In the first example, we write@result.should.be.a.kind_of. Why not kind.of? If I want to test that floats are roughly equal, I’d have said @result.should.be.close value. Why not close.to value?
Trivial details, but it means that I can’t just write tests using my knowledge of English—I have to look things up. ANd if I have to do that, why not just use a language/API that is closers to the domain of specifications and testing? Chris’s work is great, but it illustrates how a DSL that pretends to be English can never really get there. The domain of his language is software development—it would be perfectly OK to produce a DSL that makes sense in that domain.
RSpec is another behavior-driven testing framework. Here’s part of a specification (or should it be test?).
describe "(empty)" do
it { @stack.should be_empty }
it_should_behave_like "non-full Stack"
it "should complain when sent #peek" do
lambda { @stack.peek }.should raise_error(StackUnderflowError)
end
it "should complain when sent #pop" do
lambda { @stack.pop }.should raise_error(StackUnderflowError)
end
end
Another nice, readable piece of code, full of clever Ruby tricks. But, again, the attempt to create a natural language feel in the DSL leads to all sorts of leaks in the abstraction. Look at the use of should. We have should be_empty. Here, the actual assertion is (somewhat surprisingly) “should be_”. That’s right—the be_ part is really part of the should, indicating that what follows the underscore is a predicate method to be called (after adding a question mark, so we’d call @result.empty? in this case). Then we have another way of using _should_ in the phrase it_should_behave_like—all one word. Then there’s a third way of using should when we reach should raise_error. And, of course, all these uses of _should_ differ from the use in test/spec, even though both strive for an English-like interface. The same kinds of dissonance occur with the use of it in the first three lines (it {...} vs.it_should_... vs. it "...").
It’s a Domain Language
Just to reiterate, I’m not bashing either of these testing frameworks—they are popular and I’m in favor of anything that brings folks to the practices of testing.
However, I am concerned that the popularity of these frameworks, and other similar uses of English-as-a-DSL, may lead developers astray. Martin Fowler writes about fluent interfaces. I think his work might have been misunderstood—the fluency here is programmer fluency, not English fluency. It’s writing succinct, expressive code (and, in particular, using method chaining where appropriate).
The language in a DSL should be the language of the domain, not the natural language of the developer. Resist the temptation to use cute tricks to make the DSL more like a natural, human language. By doing so you might add to its readability, but I can guarantee that you’ll be taking away from its writability, and you’ll be adding uncertainty and ambiguity (the strengths of natural languages). The second you find yourself writing
def a
self
end
so that you can use “a” as a connector in
add.a.diary.entry.for("Lunch").for(August.10.at(3.pm))
you know you’ve crossed a line. This is not longer a DSL. It’s broken English.
Sunday, January 27, 2008
Pragmatic Dave on Passion, Skill and 'Having A Blast'
Link: Pragmatic Dave on Passion, Skill and 'Having A Blast'
At QconLondon 2007 Jim Coplien spoke with “Pragmatic” Dave Thomas for InfoQ. This energetic 30-minute interview runs the gamut of Dave’s wide-ranging interests: ‘agile’ publishing; how to turn what you love doing into a book; programming (and methodology) monocultures; staying limber with code “katas”; and advice for academics: help your students live with the passion of a 5-year old!
Monday, January 7, 2008
A loud "Huzzah!" was heard throughout the land
Eric Hodel is giving RDoc some love. You can’t imagine how happy that makes me.
When I first wrote RDoc, I was trying to find a way of solving two problems:
- Adding comments to the largely uncommented C source of Ruby, and
- Providing a means for library writers easily to document their creations.
I’d just finished the PickAxe, and I wanted to take the work Andy and I had done reverse engineering the Ruby API and add it back into the interpreter source code.
I set myself constraints with RDoc and ri:
- it should produce at least some documentation even on totally uncommented source files
- it should extract tacit information from the program source (for example guessing good names for block parameters by looking for yield statements inside methods)
- the markup in the source files should be unobtrusive. In the typical case, someone reading the source should not even notice that the comments follow markup conventions
- it should only use libraries that come pre-installed with Ruby
- the documentation it produced should be portable across machines and architectures
- it should allow incremental documentation. Libraries that you install over time can add methods to existing classes. As you add these libraries, the method lists in the classes you extend should grow to reflect the changes
- it should be secure. People pushed many times to add the ability to execute code during the documentation process. I didn’t want to have code run on an end user’s machine during a process that ostensibly was simply installing documentation (particularly as these installations often ran as root)
- it should be throw-away
The last one might be a surprise, but the real objective of RDoc wasn’t the tool. The real objective was to set a standard that meant that future libraries would get documented in a consistent and usable way. And so RDoc and ri compromised like crazy. Rather than a database or some complex binary format, they used a set of directory trees in the user’s filesystem to store documentation. This documentation, which is basically a set of Ruby objects, was stored using YAML, rather than marshaled objects or Ruby source. Even though YAML is slow, it is more portable than marshaled objects, and more secure than Ruby source. The parser in RDoc was a wild hack on the parser in irb. This means it performs a static, not dynamic, analysis and that it is sometimes confused by edge cases in Ruby syntax. So be it.
But the very worst part of RDoc/ri is the output side. I wanted to be able to produce output in a variety of formats: HTML, plain text, XML, chm, LaTeX, and so on. So the analysis side of RDoc produces a data structure, and passes it to the output side. Here I made a stupid design decision. What RDoc generates internally is basically nested hashes. This has a couple of major advantages. In particular, there’s a kind of fractal property when traversing it: it doesn’t matter how deep you are in the structure—all you pass to the next routine down is a hash. But it has a major downside—it’s a bitch to work with. If I were doing it again, I’d use Structs.
Finally, there’s the generation of the output itself. I needed a templating system and, for what seemed like good reasons at the time, I wrote my own. It was only a handful of lines of code initially. It’s still only a couple of hundred. It did a few things well, but ultimately it was ugly as sin. But now, as Erb has become something of a standard, it is definitely the right time to replace it.
RDoc and ri are, in a way, the ultimate stone soup. The code itself is not the output of the project. The real output is the thousands of libraries that are now self-documenting. Eric and the crew are busy on the stew, replacing the stones with real and tasty ingredients. When they are finished, we’ll be able to use all that library documentation in remarkable new ways. So, a big thank you to Eric and Seattle.rb, and to all the Ruby coders who’ve created such a great base of documentation for us all.
Here’s to RDoc 2.0.
Tuesday, January 1, 2008
Pipelines Using Fibers in Ruby 1.9—Part II
In the previous post, I developed a class called PipelineElement. This made it relatively easy to create elements that act as producers and filters in a programmatic pipeline. Using it, we could write Ruby 1.9 code like:
10.times do
puts (evens | multiples_of_three | multiples_of_seven).resume
end
The construct in the loop is a pipeline containing three chunks of code: a generator of even numbers, a filter that only passes multiples of three, and another filter that passes multiples of seven. Numbers are passed from the producer to the first filter, and then from that filter to the next, until finally popping out and being made available to puts.
However, creating these pipeline elements is still something of a pain. It turns out that we can simplify things when it comes to creating filters. In the implementation I’ll show here, we’ll only handle the case of simple transforming filters—filters that take an input, do something to it, and write the result to the filter chain.
Let’s revisit the PipelineElement class
class PipelineElement
attr_accessor :source
def initialize
@fiber_delegate = Fiber.new do
process
end
end
def |(other)
other.source = self
other
end
def resume
@fiber_delegate.resume
end
def process
while value = input
handle_value(value)
end
end
def handle_value(value)
output(value)
end
def input
source.resume
end
def output(value)
Fiber.yield(value)
end
end
The process method is the driving loop. It reads the next input from the pipeline, then callshandle_value to deal with it. In the base class, handle_value simply echoes the input to the output-real filters subclass PipelineElement and subclass this method.
Let’s make a small change to the handle_value method.
def handle_value(value)
output(transform(value))
end
def transform(value)
value
end
By doing this, we’ve split the transformation of the incoming value into a separate method. And the work done by this method no longer uses any of the state in the PipelineElement object, which means we can also do it in a block in the caller’s context. Let’s change our PipelineElement class to allow this. We’ll have the constructor take an optional block, and we’ll use that block in preference to thetransform. Here’s another listing, showing just the changed methods.
class PipelineElement
def initialize(&block)
@transformer = block || method(:transform)
@fiber_delegate = Fiber.new do
process
end
end
# ...
def handle_value(value)
output(@transformer.call(value))
end
end
This illustrates a cool (and underused) feature of Ruby. Method objects (created with the method(...)call) are duck-typed with proc objects: we can use .call(params) on both. This is a great way of letting users of a class change its behavior either by subclassing and overriding a method, or by simply passing in a block.
With this change in place, we can now write transforming filters using blocks. This is a lot more compact that the previous subclassing approach.
class Evens < PipelineElement
def process
value = 0
loop do
output(value)
value += 2
end
end
end
evens = Evens.new
tripler = PipelineElement.new {|val| val * 3}
incrementer = PipelineElement.new {|val| val + 1}
5.times do
puts (evens | tripler | incrementer ).resume
end
This outputs 1, 7, 13, 19, and 25.
Different Kinds of Filter
This approach works well if all we want is transforming filters. But what if we would also like to simplify filters that either pass of don’t pass values based on some criteria? A block would seem like a great way of specifying the condition, but we’ve already used our one block parameter up. Subclassing to the rescue. We can create two subclasses, Transformer and Filter. One sets the @transformer instance variable to any block it is passed. The other sets @filter. Here’s the relevant code:
class PipelineElement
attr_accessor :source
def initialize(&block)
@transformer ||= method(:transform)
@filter ||= method(:filter)
@fiber_delegate = Fiber.new do
process
end
end
# ...
def handle_value(value)
output(@transformer.call(value)) if @filter.call(value)
end
def transform(value)
value
end
def filter(value)
true
end
end
class Transformer < PipelineElement
def initialize(&block)
@transformer = block
super
end
end
class Filter < PipelineElement
def initialize(&block)
@filter = block
super
end
end
Thus equipped, we can write:
tripler = Transformer.new {|val| val * 3}
incrementer = Transformer.new {|val| val + 1}
multiple_of_five = Filter.new {|val| val % 5 == 0}
5.times do
puts (evens | tripler | incrementer | multiple_of_five ).resume
end
Moving The Blocks Inline
Our final hack lets us move the blocks directly into the pipeline.
Let’s look at the actual pipeline code:
puts (evens | tripler | incrementer | multiple_of_five ).resume
Those pipe characters are simply calls to the | method in class PipelineElement. And methods can take block arguments, right? So what stops us writing
puts (evens | {|v| v*3} | {|v| v+1} | multiple_of_five ).resume
It turns out that Ruby stops us. The brace characters are taken to be hash parameters, not blocks, so Ruby gets its knickers in a twist. Fortunately, that’s easily fixed by making the method calls explicit.
puts (evens .| {|v| v*3} .| {|v| v+1} .| multiple_of_five ).resume
Now we just need to make the | method accept an optional block. If the block is present, we use it to create a new transformer.
def |(other=nil, &block)
other = Transformer.new(&block) if block
other.source = self
other
end
Ruby 1.9 lets you chain method calls across lines, so we can tidy up our pipeline visually.
5.times do
puts (evens
.| {|v| v*3}
.| {|v| v+1}
.| multiple_of_five
).resume
end
A Palindrome Finder
Let’s finish with another trivial example. We’ll create a generic producer class that takes a collection and passes it, one element at a time, into the pipeline.
class Pump < PipelineElement
def initialize(source)
@source = source
super()
end
def process
@source.each {|item| Fiber.yield item}
nil
end
end
Now we can write a simple palindrome finder (a palindrome is a word which is the same when spelled backwards).
words = Pump.new %w{Madam, the civic radar rotator is not level.}
is_palindrome = Filter.new {|word| word == word.reverse}
pipeline = words .| {|word| word.downcase.tr("^a-z", '') } .| is_palindrome
while word = pipeline.resume
puts word
end
This outputs: madam, civic, radar, rotator, level.
But what if we instead want to show each word in the input stream, and flag it if it is a palindrome? That’s easily done, but we won’t do it the easy way. Instead, let’s show a more convoluted method, because it might be useful in the general case.
There’s no law to say that a transformer that receives a string as input has to write a string as output. It could, if it wanted to, write an array. Or a structure. So we could write:
WordInfo = Struct.new(:original, :forwards, :backwords)
words = Pump.new %w{Madam, the civic radar rotator is not level.}
normalize = Transformer.new {|word| [word, word.downcase.tr("^a-z", '')] }
to_word_info = Transformer.new do |word, normalized|
reversed = normalized.reverse
WordInfo.new(word, normalized, reversed)
end
formatter = Transformer.new do |word_info|
if word_info.forwards == word_info.backwords
"'#{word_info.original}' is a palindrome"
else
"'#{word_info.original}' is not a palindrome"
end
end
pipeline = words | normalize | to_word_info | formatter
while word = pipeline.resume
puts word
end
This outputs
'Madam,' is a palindrome
'the' is not a palindrome
'civic' is a palindrome
'radar' is a palindrome
'rotator' is a palindrome
'is' is not a palindrome
'not' is not a palindrome
'level.' is a palindrome
So, What’s the Point?
>
Is this a great way of writing a palindrome finder? Not really. But…
What we’ve done here is turned the way a program works on it’s head. We’ve written chunks of isolated code, each of which either filters or transforms an input. We’ve then independently knitted these chunks together. That’s a high degree of decoupling. We can also leave it until runtime to determine what gets put into the pipeline (and the order that it appears in the pipeline), which means we can move more power into the hands of our users.
Could we have done all this without Fibers? Of course. Could we do it without Ruby 1.9? Absolutely. But sometimes factors come together which lead us to experiment with new ways of thinking about our code.
This pipeline stuff is not revolutionary, and it isn’t generally applicable. But it’s fun to play with. And, for me, that’s the main thing.
A Wee Postscript
All this content is stuff that I decided not to include in the third edition of the PickAxe. It didn’t work in the section on fibers, because it uses programming techniques not yet covered. It didn’t work later because, as an example of various programming techniques, it is just too long.
Subscribe to:
Posts (Atom)